

Defining Observability
If your business depends on complex, interconnected computer systems, you might have heard the word “observability” in the context of system design. Many business owners understand the basic idea of observability and appreciate that it can be an asset. However, digging deeper into the concept of observability and its specific applications to system design and maintenance gives insights into its applicability.
System administrators, support staff, developers, and other IT professionals need to understand observability in theory and practice. Business leaders should understand the state of their computer systems, in terms of daily operations and real-time performance, especially in retrospect, after an attack, system failure, or unexpected service disruption.
For a 21st-century business to succeed in an increasingly automated, optimized environment, all stakeholders in the computerized aspects of a business must be in sync regarding how the system works and the implications of its performance on essential business processes.

Observability refers to the extent to which you can determine a system’s internal state based on its outputs, meaning the signals it sends to users, debuggers, or support specialists. Observability is a quality of the system itself, regardless of whether anyone is watching it at any specific time.
Monitoring is the active process of obtaining data about an observable system, such as when an IT service technician runs a diagnostic to find out why a network is down, or a computer has crashed.
Visibility refers to the extent to which people can perceive what is happening in observable systems.
The Observability Concept
To illustrate the concept, consider an old-fashioned analog pocket watch. Typically, only the face, the hands, and the winding stem are observable. A user can find out that the watch has stopped by looking at its face or holding it to their ear to tell if it is ticking.
By looking at the watch, a user might be able to determine that it is not operational but lack information about the gears and internal mechanism. The inside is, for practical purposes, a “black box.” Imagine, in contrast, if the watch’s owner could see through the back and observe the gears and springs in operation.
Software designers who incorporate observability into their processes are like watchmakers who allow users to open the back of the watch and peer inside. Well-crafted, maintainable computer code does more than carry out functions. It generates and directs information about its processes, telling maintenance technicians, engineers, and users:
- Which requests it received and when it received them
- How and when the program executed the request
- Whether the program’s action was successful
- What errors, if any, occurred during the process
- What action, if any, should happen next
Incorporating observability into the program from the start of a project makes code maintenance and troubleshooting less error-prone and more efficient. Having an observable system and effective monitoring capability is vital because the actions you might need to take in response to an incident can be time-sensitive.
Functions of Observability ⚙️

The quality of observability in computer architecture and software design adds to the information-processing requirements of every observable process, increasing memory requirements and processing time. Invite stakeholders who might be skeptical about the need for observability to consider the many benefits of observability, such as:
- Providing timely information to customers and employees regarding computer issues
- Protecting information systems against cyberattacks and user errors
- Reducing hourly costs for support personnel
- Reducing inefficiencies and downtime due to computer software problems
- Facilitating compliance with any governmental standards or regulations
- Identification of the cause of a system malfunction in the case of litigation
- Supporting automated diagnostic, repair, and adaptive control processes
In summary, when your IT department has accurate, comprehensive, and readily interpretable information about the system’s internal state, you will be more effective at solving IT problems.
The History of Observability in Computational Architecture 📜
Observability is at the core of computer science and programming development. A central processing system with definable internal states is the essential quality that separates a programmable computer from a simple machine. Moreover, computer programmers and debuggers need access to those internal states to predict and control how the system operates.
Programmers use their understanding of the computer’s internal state to predict how computers will behave given specific commands in specific circumstances. Malfunctions and instabilities occur when those assumptions no longer hold. Observability gives troubleshooters the tools they need to determine what went wrong or predict what will go wrong.
In the early days of computer history, a computer “bug” might be a literal moth damaging an internal computer component. However, in modern computers, a bug is usually a programming error or the failure of a program to handle unusual situations. In each case, the underlying question is the same: why is the system not working the way we expect it to?
Early computer programs could take a step-by-step approach to data processing and problem-solving. For example, when debugging a single program following instructions in sequence, it could be relatively easy to figure out where a program failed and why.
Modern computer systems involve multiple interconnected computers, each of which can contain multiple processor cores running programs simultaneously. The complexity of modern computer systems gives rise to bottlenecks, communication breakdowns, and other challenges that require attention to interrelated information sources.
Examples of Observability in Systems
You can see observability in action by watching what your computer does when a program crashes or during an ongoing operation like a system update or a virus scan. A window in your system might provide an error code or a description of a process that failed to execute. An antivirus scanner may tell you which file it is scanning, and an updater will tell you which files it is installing and when user action is required.
Imagine if these processes occurred entirely in the background without any feedback. The user would not know what was happening or what to do about it. Similarly, if you or your support staff can see at a glance how every automated process is doing, you can identify potential bottlenecks, respond to warnings, and address performance issues.
Increasing Observability Through Monitoring
Monitoring and observability are closely related but distinct concepts. Observability is only useful to the extent that someone is observing, either a human technician or an automated process that can respond to the system it is monitoring. Effective monitoring requires a combination of trained human staff and appropriate computer tools.
Human observers are fallible and can only keep track of so many sources of information at once. A technician that has to keep track of a dozen or more tabs on their computer screen can easily overlook the telltale signs of a bug even if it is observable.
💡 What is the difference between observability and monitoring? Read one of our articles.

Ensuring Visibility of Data in Observable Systems
Making the state of a computer system observable does not necessarily mean the data in that system will be interpretable or actionable. Do system administrators and support staff have to wade through a disorganized muddle of data? If so, they will not be able to identify the critical alerts, errors, and other data they need to keep the system running smoothly.
A well-designed, observable system should include the following:
- A user-friendly interface that presents information in an accessible and readable format.
- Robust data visualization techniques that allow users to easily perceive distinctions between different types of data and cause high-priority data to stand out.
- A responsive system that allows users to control which information they see and how the system presents it.
- Effective documentation and training materials that enable staff to monitor, search, and interpret system data.
Businesses can increase visibility by archiving or deleting data once it is no longer relevant. Support staff should know the data retention policy so they can anticipate what data will be readily available and know how to retrieve archived data when needed.
Data Sources in Observable Systems
One of the ways an observability platform can streamline the monitoring process is to present data about the observable aspects of your computer system in an organized way with a user-friendly interface. An observable system should include mechanisms for data collection, automated analysis, and data visualization that enhance human-computer interaction throughout the monitoring and troubleshooting process.

Logging Events
Every time a relevant computer program or module receives a request to carry out a specific request, your system should log the event, so a record persists even if the computer fails or the program crashes. A log of all system events, complete with warning messages about any unexpected activity, will be a starting point for debugging.
Tracking Requests and Processes
Individual processes occur within larger chains of processes that accomplish overarching tasks. Industry professionals call individual processes in a chain “spans.”
You can consider a trace to be like a bridge across a chasm. Each span takes the process one step closer to completion. The trace, in its entirety, crosses the chasm.
The usefulness of a trace becomes apparent when you consider all the things that can go wrong during a process. Imagine that an accident blocks one lane of traffic on a bridge. If you know exactly where the accident occurs, perhaps by having a helicopter fly over the bridge, you can direct repair crews to the bridge and diver traffic to alternative bridges.
Measuring System Performance
Even if you have a fully observable system, how do you know which events or traces to monitor? A computer system should have software that evaluates system process completion rates, latencies, and error rates. These metrics are crucial for preventative and retrospective maintenance and determining the effectiveness of any changes made to your automated business process es.
How to Achieve Observability in Your Information Systems
The best practice for increasing observability in your system is similar to many other project management challenges:
- Assess the needs of your business.
- Plan a system architecture that meets those needs.
- Identify tools that allow you to implement and maintain the new system.
- Assemble a team with the experience and talent to install and implement the new system.
- Introduce your staff to the new system and train them to use it effectively.
- Monitor the system in operation and make changes as necessary.

Experts in system design with practical business activities are indispensable at every step in the process. Implementing a system overhaul requires the ability to relate computer science principles with a real-world business’s practicalities. An expert in observable architectures could guide system development by finding solutions to problems such as:
- Determining which data sources the staff needs to monitor and the process for monitoring data
- Identifying specific threats and maintenance issues that the observable system needs to detect and respond to
- Evaluating software tools and determining their role within the system
- Fostering a culture of diligence and compliance among users of the new system
For example, one decision you will have to make is whether to rely on a small set of observability tools or to integrate and incorporate a wider variety of tools into your system. Will you use the same software toolkit to identify shipping bottlenecks that you use to detect discrepancies in payroll or security?
Using a small number of programs for creating logs, monitoring operations, curating data, etc., allows for more standardization across your business operations and does not require your employees to cross-train on a multitude of different programs.
However, each monitoring and data processing tool has features that could be particularly helpful for specific areas of your business. An IT professional can help you evaluate your options and develop ways to integrate software tools into a coherent plan for an observable architecture.
💡 Check Top 10 Observability Tools to Pay Attention to in 2023
Make Your Information System Observable, Maintainable, and Reliable with Acure
Observability and efficiency are the hallmarks of Acure.io, which sells on a software-as-a-service basis. In Acure.io one screen contains all your data and conveniently show your IT with all of the connections and health metrics.
Thanks to automation services Acure maps all your data and automatically updates and builds connections if new elements are added. All you have to do is watch the topology tree and let Acure alert you when the system needs some attention.
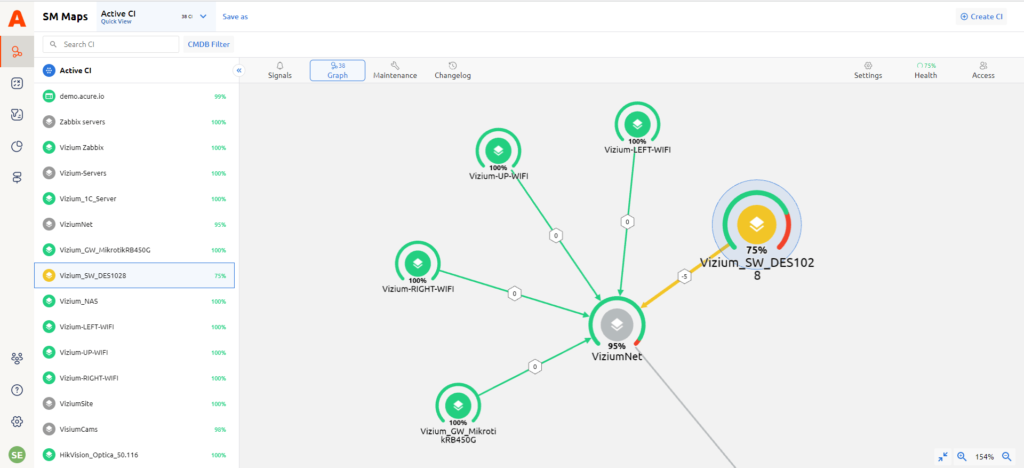
After any changes in the topology, the health of the system is instantly recalculated, coloring the entire tree appropriately. If the health of the root configuration item turns red, you will see in detail which factors most negatively affect the object and go through the branches to eventually come to the element that affected the health of the entire system.
👉 Do you want to improve your obsevability and make your data more clear? Create your Userspace in Acure.









